Let us try to understand the problem of vanishing gradient with the help of sigmoid function. The issue of vanishing gradient is also the reason why sigmoid function was not used extensively. We can say that one
of the drawbacks of using sigmoid function is vanishing gradient.
The equation of sigmoid function is
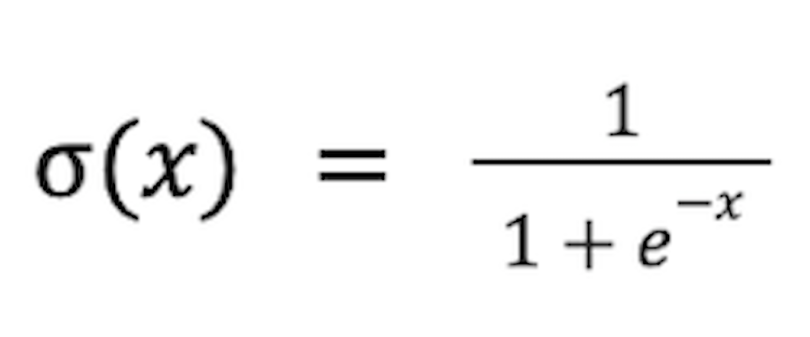
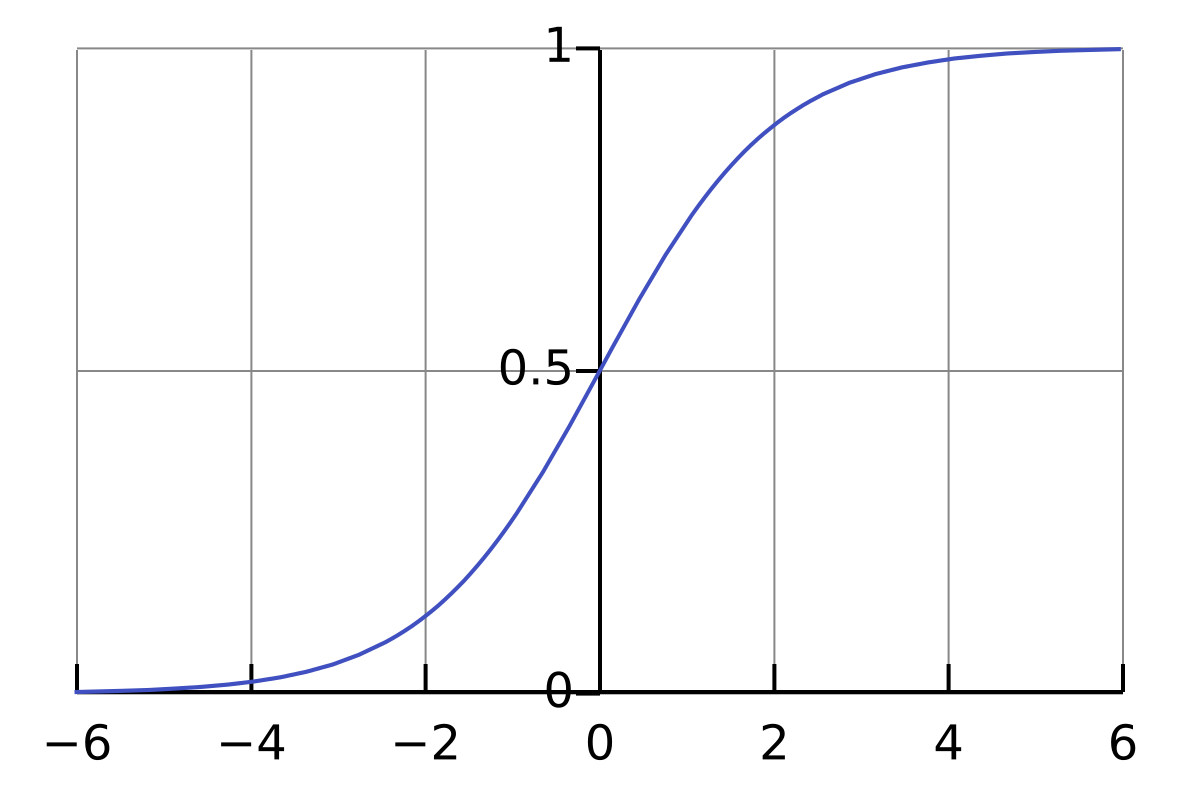
This is a logarithmic function which gives the output as 0 or 1.
Imagine we are trying to train a model using perceptron. We have assigned small initial weights. The activation function we have selected sigmoid, and all the calculations are done now. We get our loss function. Now
we need to feed the loss function back to adjust the weights of the input. This is known as backward propagations. We use gradient descent to reach the global minima so as to minimize the loss. The derivative of the sigmoid is used in gradient descent to calculate the gradient—a direction and speed for weight updates. Without the derivative, the model wouldn’t know how to change the weights effectively. The derivative of the activation function (like sigmoid) helps to determine how much to adjust the weights. The new weight is dependent on the derivative of the old weight.
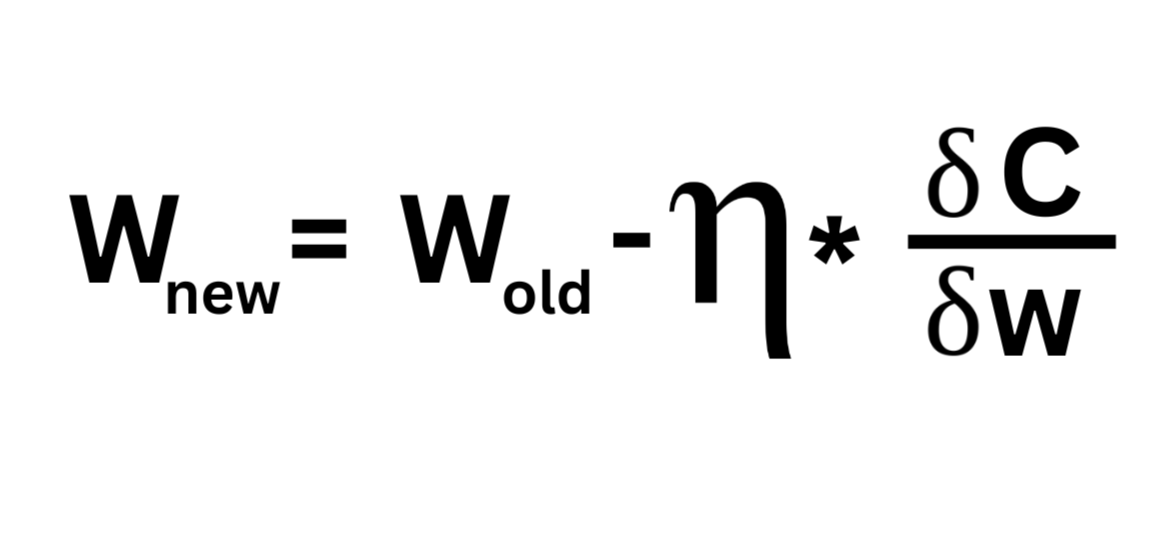
The derivative helps us understand if the weight needs to be adjusted in a larger proportion or a smaller proportion.
This change in speed is calculated using the derivative of the sigmoid:
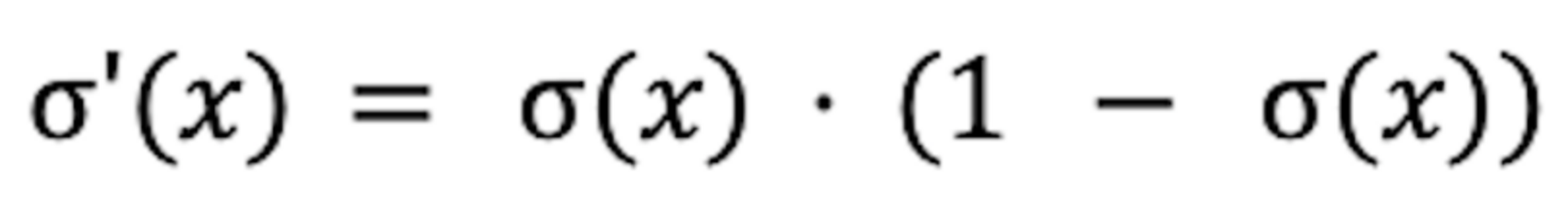
Now if we get zero in calculation before we reach the activation function.
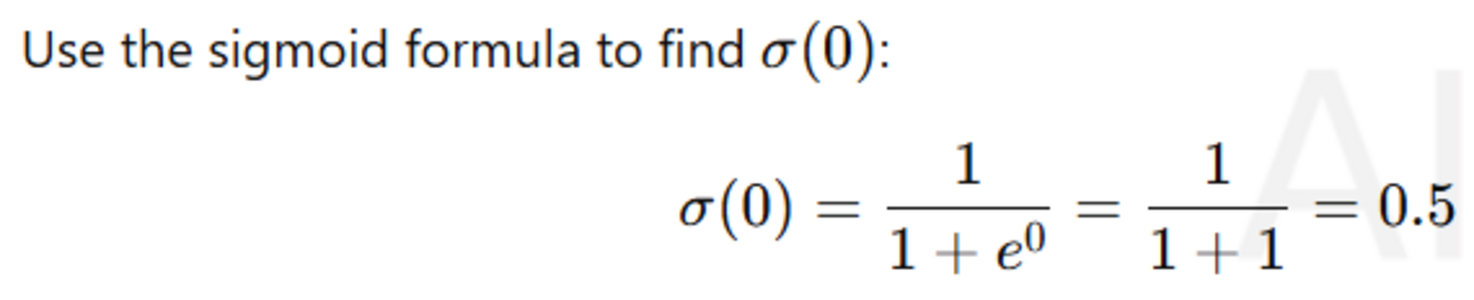
The derivative that we get would be
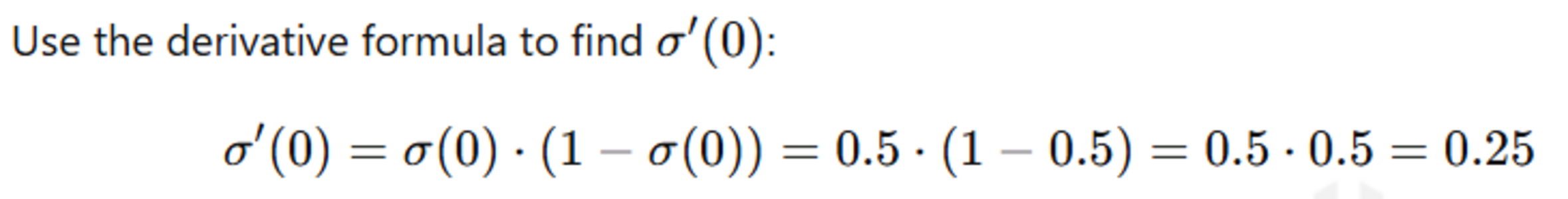
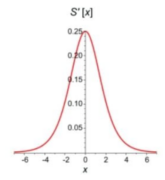
Likewise if we plot different values of sigmoid we get a graph of the derivative.
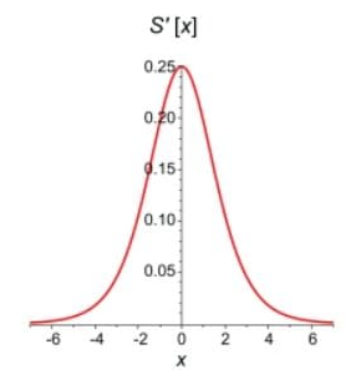
So the highest change in the weights will be when the derivative is 0.25 and the lowest can be 0. This range will help in deciding how much the gradient descent can change to move on to the next weight.
If we carefully see the weight updation formula we are subtracting from the older weight and so if we have a lot of data for learning and a lot of calculations to be done. The weight will go on decreasing. As the weight becomes very small(near zero), there would not be much difference between the new weight and the old weight. So the gradient descent will be moving very slowly towards global minima. This will unnecessarily consume a lot of resources. This is known as vanishing gradient.
The vanishing gradient problem also occurs in hyperbolic tangent (tanh) activation function as the derivatives fall within the range of 0 and 1.
How can we find out this issue?
- By observing the weights converging to 0 or stagnation in the training epochs.
- If the loss function fails to decrease significantly
- Visualization techniques, such as gradient histograms or norms, can help in assessing the distribution of gradients.
How can we solve the issue?
Normalization: The input that is received can be normalized. Helps in accelerating the calculations thereby faster convergence.
Using other Activation function: Activation function like Rectified Linear Unit (ReLU) can be used. The gradient is 0 for negative and zero input, and it is 1 for positive input.
Skip Connections and Residual Networks (ResNets): Skip connections, allow the gradient to bypass certain layers during backpropagation.
Long Short-Term Memory Networks (LSTMs) and Gated Recurrent Units (GRUs): Recurrent neural networks (RNNs) architectures like LSTMs and GRUs can address the vanishing gradient problem by incorporating gating mechanisms .
Gradient Clipping: A threshold is set for gradient. We can set both upper as well as lower limit. This will prevent the gradient to become very small or very large(exploding gradient issue).
Advertisement

Advertisement
Comments